GraphQL server in Java: Part III: Improving concurrency
fetch() API), which are concurrent by default with no extra work on a developer’s side. Actually, that’s what A stands for in AJAX1.So, what’s the advantage of GraphQL?
If a web browser can make concurrent requests to multiple pieces of data at once already, why bother with GraphQL? There are some advantages:- if you need to make more than the allowed number of concurrent connections (max 2-8, see above), the browser will throttle you anyway, queuing some requests
- GraphQL prevents over-fetching and N+1 problem by returning only properties and relationships you explicitly asked for, not more, not less
- there is just one, batched request. Concurrency happens on the server side. Well, not really…
GraphQL server is not utilizing concurrency by default
The last statement is not true by default, in Java’s implementation of GraphQL server. Remember, we provided a bunch of resolvers for each non-trivial property and relationship. Just as a reminder, this is how our resolver looks like:@ComponentEach of these methods is invoked only on demand and each one is potentially heavyweight. Unfortunately, by default GraphQL engine on the server side invokes resolver methods sequentially. Therefore the overall latency is much worse compared to RESTful API (!) Restful API would take advantage of the browser’s built-in concurrency. To show how awful this behaves, I set up Zipkin and traced each resolver:
class PlayerResolver implements GraphQLResolver<Player> {
Billing billing(Player player) //...
String name(Player player) //...
int points(Player player) //...
ImmutableList<Item> inventory(Player player) //...
}
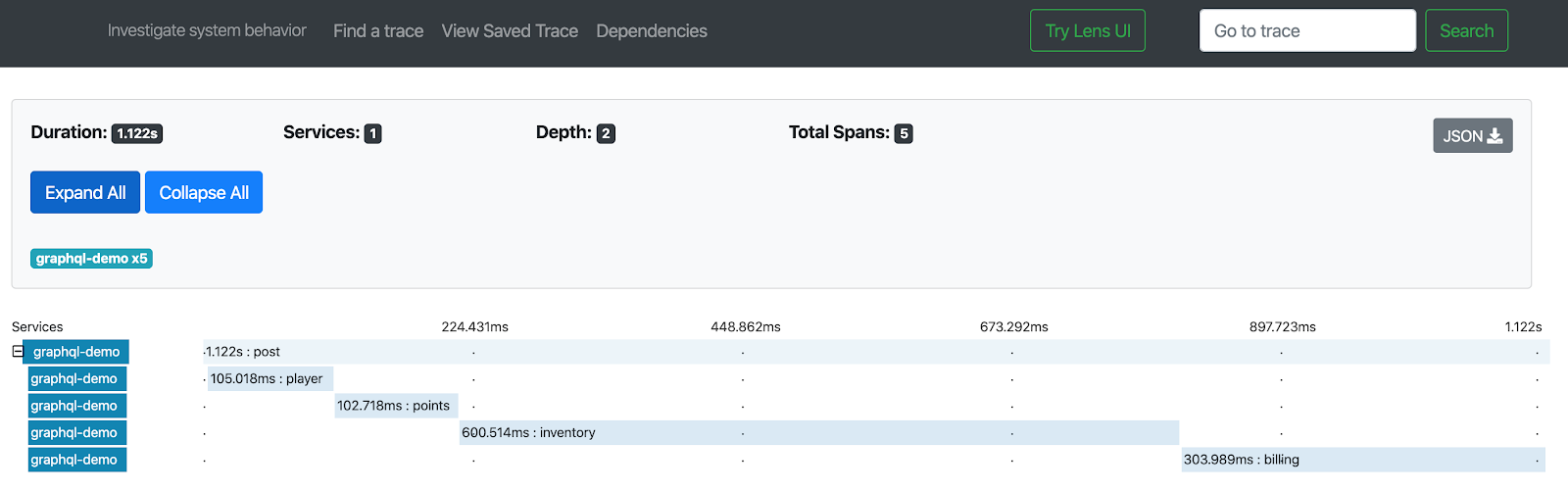
Notice how entirely unrelated resolvers are waiting for each other. Luckily this performance bottleneck is easy to fix. Turns out GraphQL engine understands
CompletableFuture!Asynchronous resolvers
Have a look at a revamped resolver API:@ComponentThe source of concurrency is not important here. It can be:
class PlayerResolver implements GraphQLResolver<Player> {
CompletableFuture<Billing> billing(Player player) //...
CompletableFuture<String> name(Player player) //...
CompletableFuture<Integer> points(Player player) //...
CompletableFuture<List<Item>> inventory(Player player) //...
}
- Java 9’s
HttpClient, - Dedicated thread pool,
- Converting from Reactor’s reactive
MonousingMono.toFuture(), - Converting from Kotlin’s [
Deferred] object usingasCompletableFuture() - …
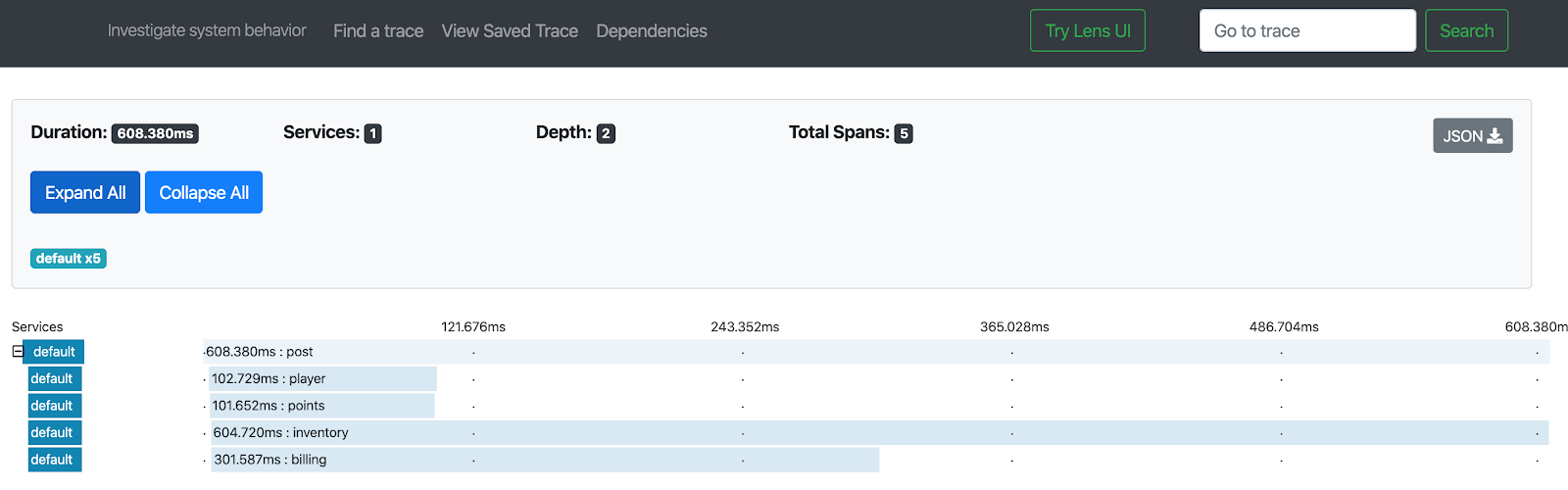
This image teaches us two things:
- the overall latency dropped from 1.1 seconds to 0.6 s - the sum of all latencies to the max of latencies
- even more importantly - did you notice how total latency is mostly affected by slow
inventoryresolver? Maybe, as a client, you can skip that property and cut latency by half?
The full source code for all articles in this series is available on GitHub, including Zipkin setup on Docker.
- Part I: Basics
- Part II: Understanding Resolvers
- Part III: Improving concurrency
- github.com/nurkiewicz/graphql-server-demo
1 - Coincidentally X in AJAX stands for… XML. Well, a technology invented by Microsoft. Tags: CompletableFuture, graphql